> pzoo = zoo ( StockIndex , order.by = rownames ( StockIndex ) )
> rzoo = ( pzoo / lag ( pzoo , k = -1) - 1 ) * 100
> ans <- do.call ( method , list ( x &#61; x , ... ) ) &#43; return ( getCov ( ans ) )} > covmat&#61;Moments(as.matrix(rzoo),"CovClassic")
> (covmat&#61;round(covmat,1))
SP500 N225 FTSE100 CAC40 GDAX HSI
SP500 17.8 12.7 13.8 17.8 19.5 18.9
N225 12.7 36.6 10.8 15.0 16.2 16.7
FTSE100 13.8 10.8 17.3 18.8 19.4 19.1
CAC40 17.8 15.0 18.8 30.9 29.9 22.8
GDAX 19.5 16.2 19.4 29.9 38.0 26.1
HSI 18.9 16.7 19.1 22.8 26.1 58.1
现在&#xff0c;我们可以可视化下面的有效边界&#xff08;和可接受的投资组合&#xff09;
> points(sqrt(diag(covmat)),er,pch&#61;19,col&#61;"blue")
> text(sqrt(diag(covmat)),er,names(er),pos&#61;4, col&#61;"blue",cex&#61;.6)
> polygon(u,v,border&#61;NA,col&#61;rgb(0,0,1,.3))
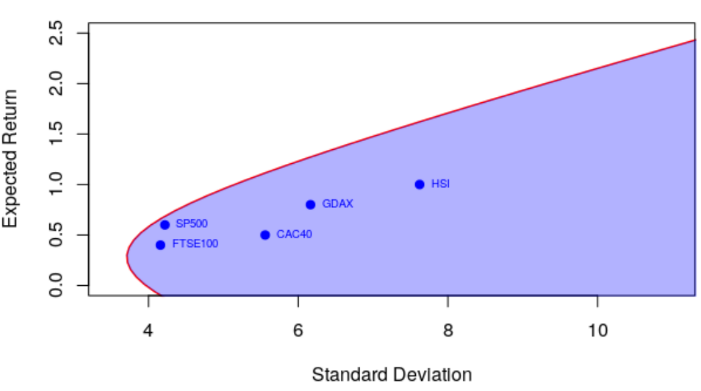
实际上很难在该图上将重要的东西可视化&#xff1a;收益之间的相关性。它不是点&#xff08;单变量&#xff0c;具有预期收益和标准差&#xff09;&#xff0c;而是有效边界。例如&#xff0c;这是我们的相关矩阵
SP500 N225 FTSE100 CAC40 GDAX HSI
SP500 1.00 0.50 0.79 0.76 0.75 0.59
N225 0.50 1.00 0.43 0.45 0.43 0.36
FTSE100 0.79 0.43 1.00 0.81 0.76 0.60
CAC40 0.76 0.45 0.81 1.00 0.87 0.54
GDAX 0.75 0.43 0.76 0.87 1.00 0.56
HSI 0.59 0.36 0.60 0.54 0.56 1.00
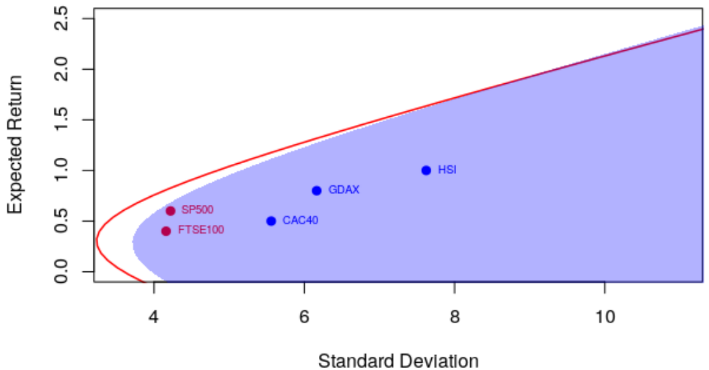
我们实际上可以更改FT500和FTSE100之间的相关性&#xff08;此处为.786&#xff09;
courbe&#61;function(r&#61;.786){ef
plot(ef$sd,ef$er,type&#61;"l",xlab&#61;"Standard Deviation",ylab&#61;"Expected Return",
points(sqrt(diag(covmat)),er,pch&#61;19,col&#61;c("blue","red")[c(2,1,2,1,1,1)])polygon(u,v,border&#61;NA,col&#61;rgb(0,0,1,.3))
}
例如&#xff0c;相关系数为0.6&#xff0c;我们得到以下有效边界
> courbe(.6)
并具有更强的相关性
> courbe(.9)
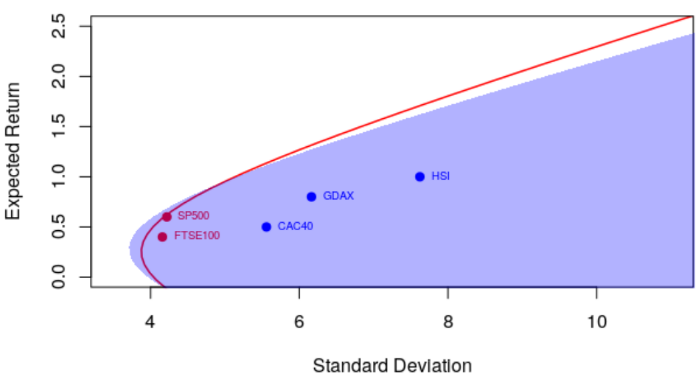
很明显&#xff0c;相关性很重要。但更重要的是&#xff0c;期望收益和协方差不是给出而是估计的。以前&#xff0c;我们确实将标准估计量用于方差矩阵。但是可以考虑使用另一个更可靠的估计器
covmat&#61;Moments(as.matrix(rzoo),"CovSde")points(sqrt(diag(covmat)),er,pch&#61;19,col&#61;"blue")
text(sqrt(diag(covmat)),er,names(er),pos&#61;4,col&#61;"blue",cex&#61;.6)
polygon(u,v,border&#61;NA,col&#61;rgb(0,0,1,.3))
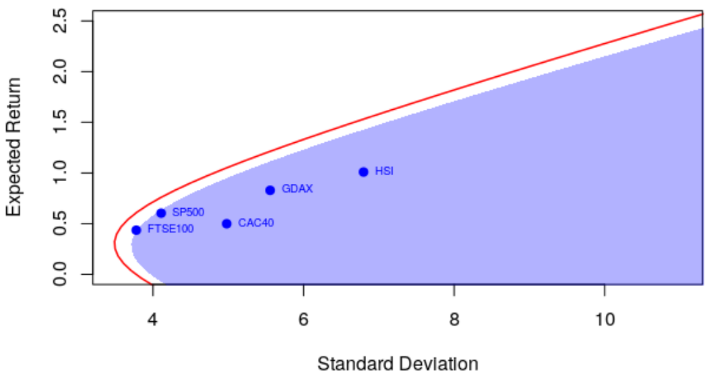
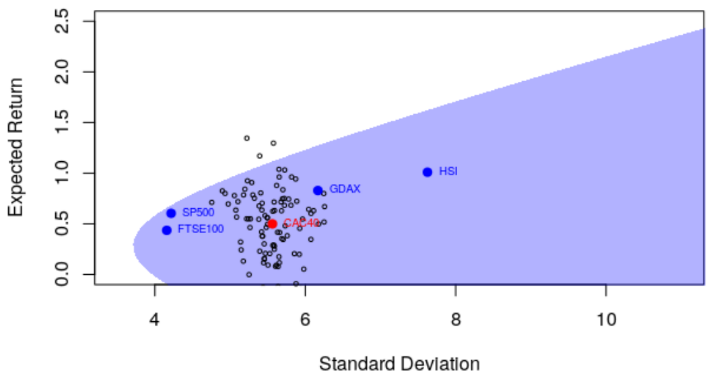
它确实影响了点的&#xff08;水平&#xff09;位置&#xff0c;因为方差现在以及有效边界都不同&#xff0c;而方差明显更低。
为了说明最后一点&#xff0c;说明我们确实有基于观察到的收益的估计量&#xff0c;如果我们观察到不同的收益怎么办&#xff1f;了解可能发生的情况的一种方法是使用引导程序&#xff0c;例如每日收益。
> plot(ef$sd,ef$er,type&#61;"l",xlab&#61;"Standard Deviation",ylab&#61;"Expected Return", xlim&#61;c(3.5,11),ylim&#61;c(0,2.5),col&#61;"white",lwd&#61;1.5)
> polygon(u,v,border&#61;NA,col&#61;rgb(0,0,1,.3))
> for(i in 1:100){
&#43;
&#43;
&#43; er&#61;apply(as.matrix(rzoo)[id,],2,mean)
&#43; points(sqrt(diag(covmat))[k],er[k],cex&#61;.5)
&#43; }
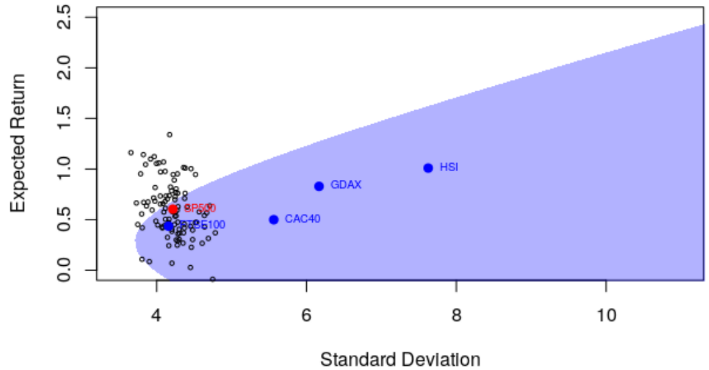
或其他资产
这是我们在&#xff08;估计的&#xff09;有效边界上得到的
> polygon(u,v,border&#61;NA,col&#61;rgb(0,0,1,.3))
> for(i in 1:100){
&#43;
&#43;
&#43;
&#43; ef <- efficient.frontier(er, covmat, alpha.min&#61;-2.5, alpha.max&#61;2.5, nport&#61;50)
&#43; lines(ef$sd,ef$er,col&#61;"red")
&#43; }
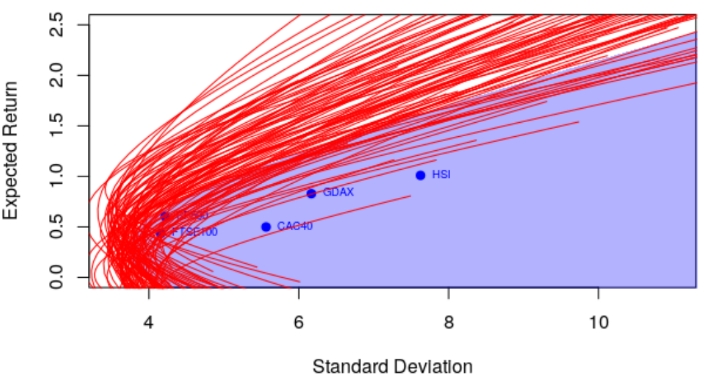
因此&#xff0c;至少在统计学的角度上&#xff0c;要评估一个投资组合是否最优是很困难的。

参考文献
1.用机器学习识别不断变化的股市状况—隐马尔科夫模型(HMM)的应用
2.R语言GARCH-DCC模型和DCC&#xff08;MVT&#xff09;建模估计
3.R语言实现 Copula 算法建模依赖性案例分析报告
4.R语言使用ARIMA模型预测股票收益
5.r语言中对LASSO回归&#xff0c;Ridge岭回归和Elastic Net模型实现
6.用R语言实现神经网络预测股票实例
7.r语言预测波动率的实现&#xff1a;ARCH模型与HAR-RV模型
8.R语言如何做马尔科夫转换模型markov switching model






 京公网安备 11010802041100号
京公网安备 11010802041100号